Another CYSO DevOps related article, focusing on better logging from in-house developed applications. This post has also been posted to the CYSO blog.
Er zijn een aantal zaken in Software Development die snel complex kunnen worden, waarbij ik persoonlijk data opslag één van de belangrijkere vind. Voor het configureren van (Python) applicaties hebben we al eerder een oplossing bedacht: omniconf. Het loggen binnen een applicatie kan ook ingewikkeld zijn, zeker zodra applicaties groter beginnen te worden of een platform ingewikkelder. In dit artikel zal ik aandacht schenken aan een manier om flexibel te loggen vanuit Python met fluentd.
Wat verstaan we onder loggen?
Voor een Software Developer zal het geen nieuw concept zijn: een applicatie of script voert een set taken uit. Om de voortgang van deze taken weer te geven kan er in het geval van een CLI applicatie tekst worden weergegeven naar console. Maar wat als er geen console is, omdat de applicatie wordt uitgevoerd op de achtergrond, bijvoorbeeld als cronjob of daemon?
Meestal heeft het besturingssysteem zelf een mechanisme om logs op te slaan. Unix-achtigen hebben syslog en Windows heeft de Event Log. Als laatste redmiddel kan er altijd nog gelogd worden naar een bestand. Dat laatste brengt weer extra problemen mee: bestanden kunnen groot worden, dus deze moeten periodiek worden opgeruimd, zoals met logrotate onder Linux. Allemaal zaken waar over moet worden nagedacht, en welke ingewikkelder worden zodra er meer servers in het spel zijn.
Als we kijken naar de laatste trends: het draaien van applicaties in containers, dan zien we snel dat het bovenstaande helemaal niet meer haalbaar is. (Log)bestanden in containers zijn per definitie vluchtig, tenzij specifieke maatregelen genomen worden om deze veilig te stellen door ze centraal op te slaan. Daarnaast draaien containers maar één taak, dus is het automatisch opruimen van logbestanden weer moeilijk.
Hoe los je dit op?
Een betere oplossing is bij het concept van 'loggen’ een onderscheid gemaakt kan worden tussen het aanmaken van de logs, het opslaan (en opruimen) ervan, en eventueel het doorzoekbaar maken. Daarnaast willen we als Developers graag kunnen loggen op één manier, zodat we niet constant het wiel opnieuw aan het uitvinden zijn. Als laatste willen we flexibel kunnen zijn in hoe we logs opslaan, zonder dat we daarbij wijzigingen hoeven uit te voeren in de code.
fluentd kan hierbij helpen. Het biedt een aantal tools, waarbij de daemon met dezelfde naam het belangrijkst is.
Python en logging
Voordat we dieper in gaan op fluentd, eerst even een kleine excursie. Onze use-case is een (bestaande) applicatie, welke gebruik maakt van het Python logging framework. Dit is verreweg de beste oplossing in het geval van Python. Laten we het volgende script als voorbeeld nemen:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("script")
logger.info("Dit is een log bericht met niveau INFO.")
for i in range(20):
logger.debug(
"Dit is een log bericht met niveau DEBUG en nummer {}".format(i))
logger.error("Dit is een log bericht met niveau ERROR.")
De output van dit script zal het volgende zijn:
$ python simple.py
INFO:script:Dit is een log bericht met niveau INFO.
ERROR:script:Dit is een log bericht met niveau ERROR.
In totaal worden er 22 log berichten aangemaakt in het script: één met niveau INFO, één met niveau ERROR en 20 met niveau DEBUG. Hiervan komen enkel de berichten met een niveau hoger of gelijk aan INFO terecht in de console. Stel dat we ditzelfde ook naar syslog zouden willen sturen, dan kunnen we dat als volgt toevoegen:
import logging
import logging.handlers
console = logging.StreamHandler()
syslog = logging.handlers.SysLogHandler(address="/dev/log")
logging.basicConfig(level=logging.INFO, handlers=[console, syslog])
logger = logging.getLogger("script")
logger.info("Dit is een log bericht met niveau INFO.")
for i in range(20):
logger.debug(
"Dit is een log bericht met niveau DEBUG en nummer {}".format(i))
logger.error("Dit is een log bericht met niveau ERROR.")
Dit zal de volgende berichten plaatsen op de console en in syslog:
$ python syslog.py
INFO:script:Dit is een log bericht met niveau INFO.
ERROR:script:Dit is een log bericht met niveau ERROR.
$ grep script /var/log/syslog
May 8 16:51:40 blade INFO:script:Dit is een log bericht met niveau INFO.
May 8 16:51:40 blade ERROR:script:Dit is een log bericht met niveau ERROR.
So far, so good. Maar stel dat we per log regel extra informatie willen opslaan, bijvoorbeeld in het geval van HTTP calls op een API met een limiet? In dat geval kunnen we dit doen:
...
extra_data = {"foo": "bar"}
logger.info("Dit is een log bericht met niveau INFO.", extra=extra_data)
Maar wat zien we hiervan terug in de logs?
$ python extra.py
INFO:script:Dit is een log bericht met niveau INFO.
$ grep script /var/log/syslog
May 8 16:55:01 blade INFO:script:Dit is een log bericht met niveau INFO.
Niets! We lopen hier tegen een limitatie aan van het opslaan van logs als tekst: extra data wordt niet opgeslagen tenzij we het opslaan als onderdeel van het log bericht zelf.
fluentd
Wat kan
fluentd betekenen in het bovenstaande voorbeeld? Als eerste: fluentd is makkelijk te integreren, door simpelweg een extra handler toe te voegen. We maken hierbij gebruik van de
fluent-logger module, beschikbaar op PyPi:
import logging
from fluent import handler
console = logging.StreamHandler()
console.setLevel(level=logging.INFO)
fluent = handler.FluentHandler('tag.script')
fluent_formatter = handler.FluentRecordFormatter(
exclude_attrs=('exc_info', 'stack_info', 'msg', 'args'))
fluent.setFormatter(fluent_formatter)
fluent.setLevel(level=logging.DEBUG)
logging.basicConfig(level=logging.DEBUG, handlers=[console, fluent])
...
We zien hier dat we de logs naar console limiteren tot INFO (of hoger) berichten, maar wel alle berichten naar fluent sturen. Als we op de achtergrond snel even fluentd starten via de fluentd Docker image:
docker run --rm -it -p 24224:24224/udp fluent/fluentd
Dan zien we het volgende terug in de output van fluentd:
2018-05-08T15:17:58+00:00 tag.script {"thread":140221463684928,"processName":"MainProcess","message":"Dit is een log bericht met niveau INFO.","levelname":"INFO","levelno":20,"name":"script","hostname":"blade","created":1525792678.5973475,"lineno":17,"process":31154,"filename":"fluentd1.py","threadName":"MainThread","funcName":"","exc_text":null,"pathname":"fluentd1.py","module":"fluentd1","foo":"bar","relativeCreated":16.6778564453125,"msecs":597.3474979400635}
...
De berichten worden door de fluent-logger module omgevormd naar een formaat wat fluentd snapt. Met de standaard configuratie zal fluentd alles loggen naar een bestand. We zien hierboven ons INFO bericht terug, en daar zien we ook meteen de extra data die we eerder meestuurde met dit bericht! Zoals je ziet bevat dit bericht veel meer metadata dan enkel tekst: er wordt bijvoorbeeld ook informatie opgeslagen over de locatie in het bestand waar het log bericht gemaakt werd.
Als tweede voordeel van fluentd: het instellen van de applicatie is op dit punt klaar. We kunnen nog wat verbeteren aan de manier waarop we loggen naar console (want dat is nou eenmaal handig), of de manier waarop we logging instellen, maar de configuratie is verder af. De magie begint hierna in fluentd.
Log targets
De standaard configuratie van fluentd is simpel:
<source>
@type forward
@label application
port 24224
</source>
<label application>
<filter **>
@type stdout
</filter>
<match **>
@type file
path "/fluentd/log/data.*.log"
symlink_path "/fluentd/log/data.log"
append true
</match>
</label>
De configuratie zal poort 24224 openen om berichten te ontvangen via fluent's eigen forward protocol, en voorzien van de label application. Daarna volgt de configuratie voor deze label. Via een filter wordt elk bericht naar console geprint (wat vooral handig is tijdens testen). Als laatste zal fluentd elk bericht wat overeen komt met ** opslaan in een logbestand.
Zoals al eerder gezegd: logbestanden zijn prima, totdat je applicatie ingewikkelder wordt of je schaalt naar meerdere servers. Met grep kom je een heel eind, maar het doorzoeken van veel logs kan beter. Je kan beter de berichten opslaan in een systeem wat goed overweg kan met veel data, en daarnaast ook full-text search ondersteunt, zoals
Elasticsearch.
Loggen naar Elasticsearch
Met een kleine toevoeging aan de fluentd configuratie, kunnen we alle inkomende log berichten sturen naar twee targets: een logbestand en Elasticsearch:
<source>
@type forward
@label application
port 24224
</source>
<label application>
<filter **>
@type stdout
</filter>
<match **>
@type copy
<store>
@type file
path "/fluentd/log/data.*.log"
symlink_path "/fluentd/log/data.log"
append true
</store>
<store>
@type elasticsearch
logstash_format true
logstash_prefix fluent
logstash_prefix_separator -
logstash_dateformat %Y.%m
type_name ${tag}
<buffer>
flush_mode interval
flush_interval 5s
</buffer>
</store>
</match>
</label>
Nieuw in deze configuratie: match heeft als type copy gekregen. Hiermee worden berichten doorgestuurd naar elke store die gedefinieerd wordt. Met het extra blok voor Elasticsearch zal een index worden aangemaakt met als naam fluent-YYYY.MM, waarin de berichten worden opgeslagen. De aanname wordt hier gedaan dat Elasticsearch draait op dezelfde server waar fluentd ook draait, maar dit is uiteraard configureerbaar.
Zodra de logs in Elasticsearch zitten, dan is het mogelijk om deze data te doorzoeken met tools zoals Kibana.
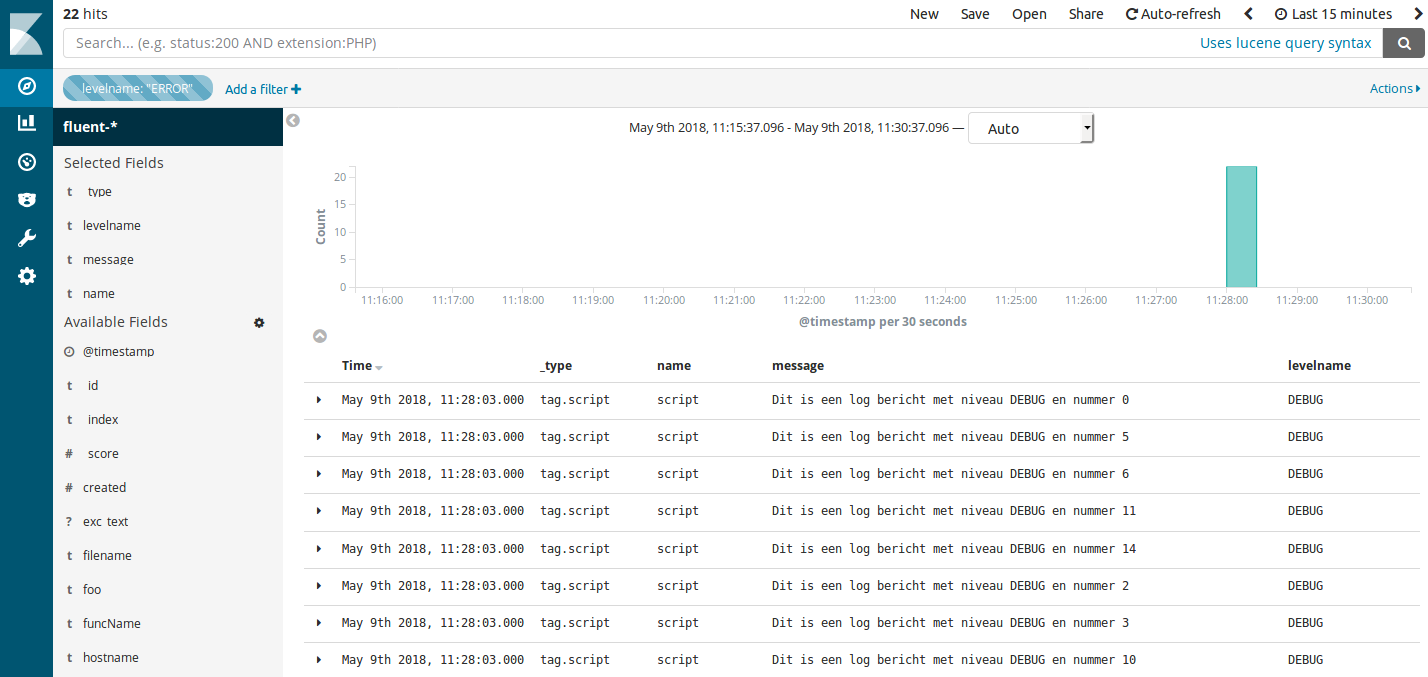
Hoe maak je dit schaalbaar?
De oplettende kijker thuis merkt op dat dit nog steeds niet echt schaalbaar is. We hebben de configuratie in de applicatie versimpeld, maar fluentd draait nog steeds op de server zelf. Hoe maak schaal je dit naar bijvoorbeeld 50 servers?
Laten we het voorbeeld van hiervoor nemen: een applicatie die logt via fluentd naar logbestanden en Elasticsearch. Om dit schaalbaar te maken heb je een aantal opties: je kan fluentd installeren op elke server, en deze direct zijn logs laten opslaan in Elasticsearch; of je installeert fluentd op een (aantal) centrale servers, laat de applicatie daarheen loggen, en deze fluentd daemons slaan de logs op in Elasticsearch.
Beide opties hebben voordelen: de eerste is het veiligst omdat fluentd intern logs zal opslaan totdat hij ze kwijt kan bij alle doelen. Mocht Elasticsearch tijdelijk onbereikbaar zijn, dan zullen de logs opgespaard worden. Nadeel van deze oplossing is dat je veel overhead hebt: elke server draait fluentd, en elke instantie verbruikt geheugen en CPU. Daarnaast moet ook de configuratie van al deze fluentd instanties beheerd worden, iets wat we nou juist wilden versimpelen.
De tweede optie is een betere balans: een (aantal) centrale fluentd nodes, welke verantwoordelijk zijn voor het verwerken van de logs en het opslaan in Elasticsearch. De kans dat logs kwijtraken als een instantie down gaat is groter, maar de overhead is ook kleiner omdat er minder fluentd instanties zijn.
Mocht het platform nog groter worden, dan zijn er combinaties te verzinnen. fluentd is namelijk in staat om logs verder door te sturen naar andere fluentd instanties, waardoor ingewikkeldere combinaties van matchen, filteren en opslag mogelijk zijn.
Wat hebben we bereikt
Het voorbeeld ging uit van een zelfontwikkelde applicatie, waarbij we het loggen los wilden koppelen van de opslag. Het loggen zelf was vrij snel te regelen, via het Python logging framework en fluent-logger. Voor de opslag hebben we gekozen voor Elasticsearch. De logs zijn in Elasticsearch te doorzoeken met andere tools, zoals Kibana. Deze oplossing kan schalen, omdat we zonder aanpassingen in de applicatie veranderingen kunnen aanbrengen in het log mechanisme, bijvoorbeeld door meer fluentd instanties te gebruiken.
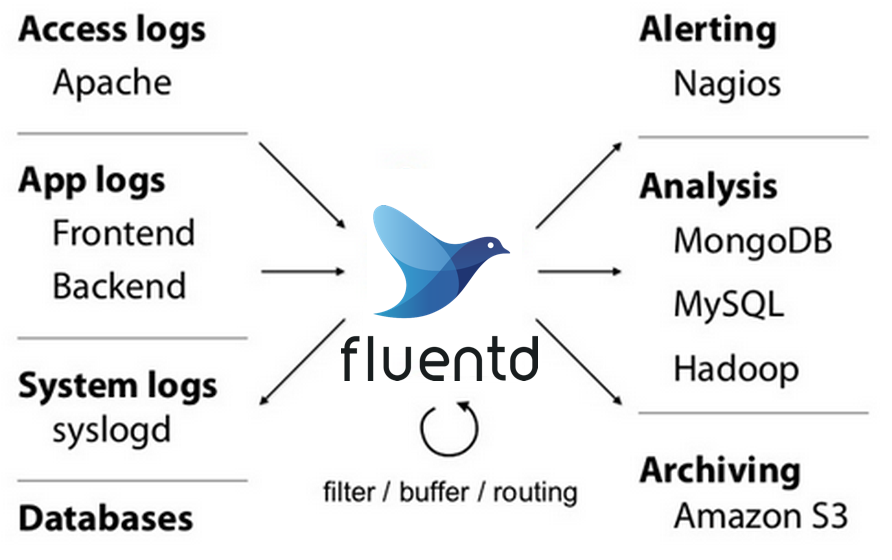
Naast het bovenstaande voorbeeld kan fluentd nog meer. Het loggen vanuit een applicatie is maar één manier waarop fluentd logs kan ontvangen, en Elasticsearch is maar één manier om ze op te slaan. fluentd is uitbreidbaar met plugins. Een ander voorbeeld kan zijn om Apache of Nginx logs te verzamelen en filteren, en deze door te sturen naar een object store zoals Amazon S3 (of diensten die hiermee compatibel zijn, zoals FUGA of Minio). En als fluentd te zwaar is voor de omgeving, kan er ook nog gebruik gemaakt worden van fluentbit, welke flexibiliteit in de vorm van plugins inruilt voor een kleiner geheugen en CPU gebruik.